
k8s中控制器详解
常见Pod控制器
- ReplicaSet:适合无状态的服务部署
用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:
(1)用户期望的pod副本数量
(2)标签选择器,判断哪个pod归自己管理
(3)当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。 - deployment:适合无状态的服务部署工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
- StatefullSet:适合有状态的服务部署。需要学完存储卷后进行系统学习。
- DaemonSet:一次部署,所有的node节点都会部署,例如一些典型的应用场景:
- 运行集群存储 daemon,例如在每个Node上运行 glusterd、ceph
- 在每个Node上运行日志收集 daemon,例如 fluentd、 logstash
- 在每个Node上运行监控 daemon,例如 Prometheus Node Exporter
用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服
务
特性:服务是无状态的
服务必须是守护进程
- Job:一次性的执行任务。 只要完成就立即退出,不需要重启或重建。
- Cronjob:周期性的执行任务。 周期性任务控制,不需要持续后台运行。
ReplicaSet
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。
ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector。
虽然ReplicaSet可以独立使用,但一般还是建议使用 Deployment 来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持rolling-update但Deployment支持)。
ReplicationController
Replication Controller 简称 RC,实际上 RC 和 RS 的功能几乎一致,唯一的一个区别就是 RC 只支持基于等式的 selector(env=dev或environment!=qa),但 RS 还支持基于集合的 selector。
1 | rc |
ReplicaSet模板说明
1 | apiVersion: apps/v1 #api版本定义 |
当然,可以通过kubectl命令行方式获取更加详细信息:
1 | kubectl explain rs |
常用的命令如下:
1 | 运行ReplicaSet |
最后,总结一下RC(ReplicaSet)的一些特性和作用:
- 在绝大多数情况下,我们通过定义一个RC实现Pod的创建及副本数量的自动控制;
- 在RC里包括完整的Pod定义模板;
- RC通过Label Selector机制实现对Pod副本的自动控制;
- 通过改变RC里Pod副本数量,可以实现Pod的扩容和缩容;
- 通过改变RC里Pod模板中的镜像版本,可以实现滚动升级;
Deployment
Deployment是kubernetes在1.2版本中引入的新概念,用于更好的解决Pod的编排问题,为此,Deployment在内部使用了ReplicaSet来实现目的,我们可以把Deployment理解为ReplicaSet的一次升
级,两者的相似度超过90%
Deployment的使用场景有以下几个:
- 创建一个Deployment对象来生成对应的ReplicaSet并完成Pod副本的创建;
- 检查Deployment的状态来看部署动作是否完成(Pod副本数量是否达到了预期的值);
- 更新Deployment以创建新的Pod(比如镜像升级);
- 如果当前Deployment不稳定,可以回滚到一个早先的Deployment版本;
- 暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后在恢复Deployment,进行新的发布;
- 扩展Deployment以应对高负载;
- 查看Deployment的状态,以此作为发布是否成功的标志;
- 清理不在需要的旧版本ReplicaSet;
详细信息可以使用如下命令:
1 | kubectl explain deploy |
Pod 依赖的控制器 RS 实际上被的 Deployment 控制着,
Pod、ReplicaSet、Deployment 三者之间的关系图如下: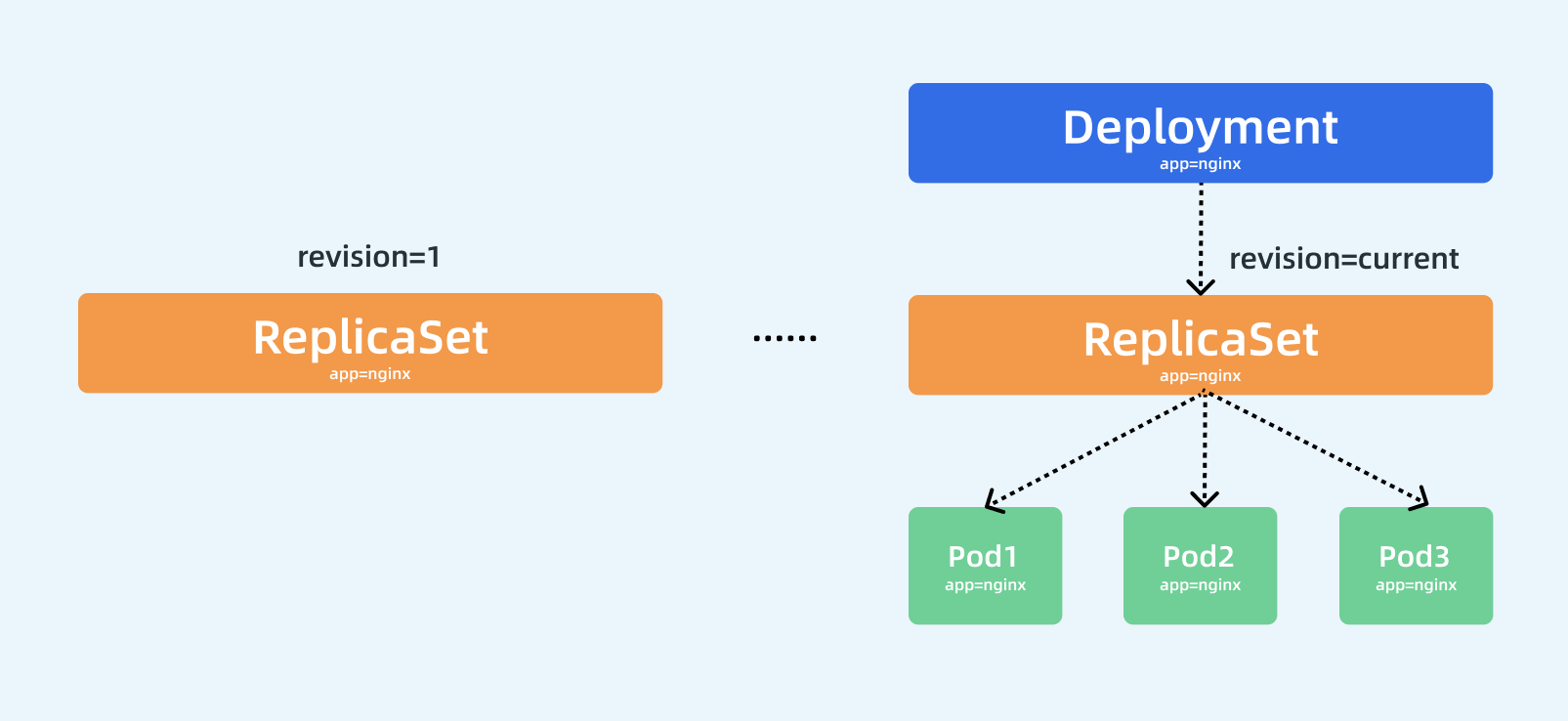
当创建一个Deployment时,它会自动创建一个ReplicaSet,然后由ReplicaSet去创建Pod(Deployment是不会自己去创建Pod)。
当需要更新Pod时,比如升级镜像版本,Deployment会先再创建一个ReplicaSet,由这个新的ReplicaSet去创建新版本的Pod,每创建一个就会在原先的ReplicaSet中删除一个,最终完成更新,注意:更新之后并不会删除之前的ReplicaSet,当发现更新错误需要回滚时,就会由旧的ReplicaSet去创建老版本的Pod;
如上图,Deployment是管理了很多个ReplicaSet的。
Deployment模板说明
基本与ReplicaSet一致。
1 | apiVersion: apps/v1 #api版本定义 |
镜像更新命令
通过命令行修改镜像版本:
1 | 升级nginx镜像版本为1.18.0 |
滚动更新
部署更新相关,可以参考关于蓝绿发布、灰度以及滚动发布的记录
金丝雀发布
Deployment控制器支持自定义控制更新过程中的滚动节奏,如“暂停(pause)”或“继续(resume)”更新操作。比如等待第一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新版本的Pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的Pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布(Canary Release)
滚动更新命令如下:
1 | 更新deployment的nginx:1.18.0-alpine版本,并配置暂停deployment |
版本回退
默认情况下,kubernetes 会在系统中保存前两次的 Deployment 的 rollout 历史记录,以便可以随时回退(您可以修改revision history limit 来更改保存的revision数)。
注意: 只要 Deployment 的 rollout 被触发就会创建一个 revision。也就是说当且仅当Deployment 的 Pod template(如.spec.template )被更改,例如更新template 中的 label 和容器镜像时,就会创建出一个新的 revision。
其他的更新,比如扩容 Deployment 不会创建 revision——因此我们可以很方便的手动或者自动扩容。这意味着当您回退到历史 revision 时,只有 Deployment 中的 Pod template 部分才会回退。
rollout常见命令
| 子命令 | 功能说明 |
|---|---|
| history | 查看rollout操作历史 |
| pause | 将提供的资源设定为暂停状态 |
| restart | 重启某资源 |
| resume | 将某资源从暂停状态恢复正常 |
| status | 查看rollout操作状态 |
| undo | 回滚前一rollout |
具体命令示例如下:
1 | kubectl rollout history deployment deploymentdemo |
更新策略
Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多一个不可用)
Deployment 同时也可以确保只创建出超过期望数量的一定数量的 Pod。默认的,它会确保最多比期望的Pod数量多一个的 Pod 是 up 的(最多1个 surge )
Kuberentes 版本v1.17.5中,从1-1变成25%-25%
查看命令如下:
1 | kubectl describe deployments.apps deploymentdemo |
DaemonSet
DaemonSet 确保全部Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有Pod。
在每一个node节点上只调度一个Pod,因此无需指定replicas的个数,比如:
- 在每个node上都运行一个日志采集程序,负责收集node节点本身和node节点之上的各个Pod所产生的日志
- 在每个node上都运行一个性能监控程序,采集该node的运行性能数据
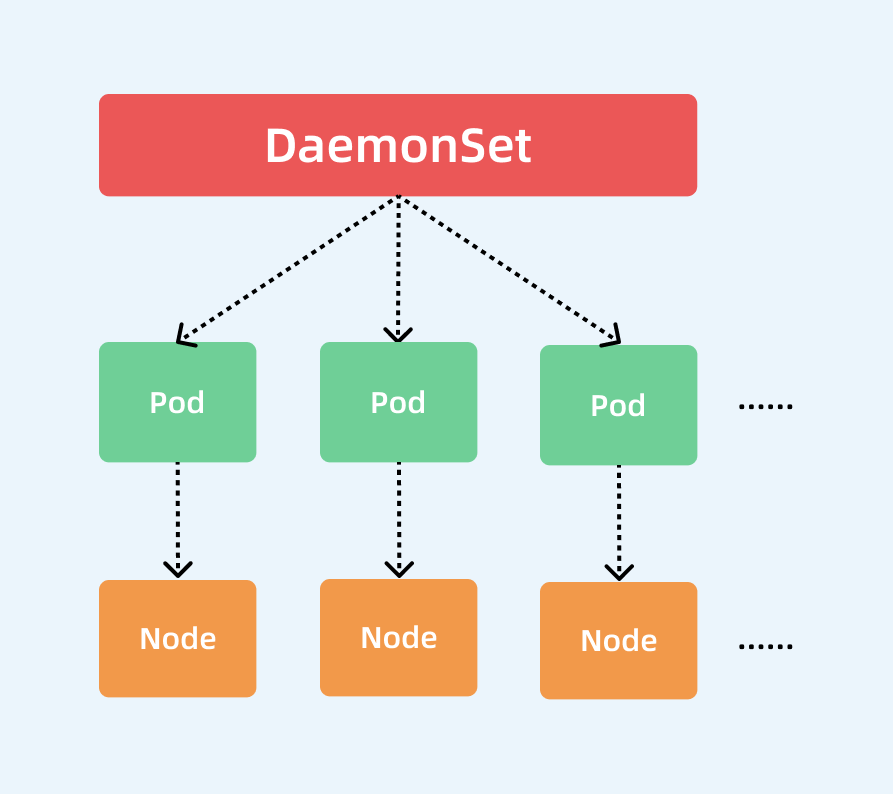
DaemonSet 控制器是如何保证每个 Node 上有且只有一个被管理的 Pod 呢?
- 首先控制器从 Etcd 获取到所有的 Node 列表,然后遍历所有的 Node。
- 根据资源对象定义是否有调度相关的配置,然后分别检查 Node 是否符合要求。
- 在可运行 Pod 的节点上检查是否已有对应的 Pod,如果没有,则在这个 Node 上创建该 Pod;如果有,并且数量大于 1,那就把多余的 Pod 从这个节点上删除;如果有且只有一个 Pod,那就说明是正常情况。
DaemonSet有两种更新策略类型:
- OnDelete:这是向后兼容性的默认更新策略。使用 OnDelete 更新策略,在更新DaemonSet模板后,只有在手动删除旧的DaemonSet pod时才会创建新的DaemonSet pod。这与Kubernetes 1.5或更早版本中DaemonSet的行为相同。
- RollingUpdate:使用RollingUpdate 更新策略,在更新DaemonSet模板后,旧的DaemonSet pod将被终止,并且将以受控方式自动创建新的DaemonSet pod。
Job与CronJob
Job 负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。而CronJob 则就是在 Job 上加上了时间调度。
Job特点:
- 一次性执行任务,类似Linux中的job
- 应用场景:如离线数据处理,视频解码等业务
模板示例:
1 | apiVersion: batch/v1 |
通过模板可知,Job 中也是一个 Pod 模板,和之前的 Deployment、StatefulSet 之类的是一致的,只是 Pod 中的容器要求是一个任务,而不是一个常驻前台的进程了,因为它是需要退出的。
另外值得注意的是 Job 的 RestartPolicy 仅支持 Never 和 OnFailure 两种,不支持 Always,由于 Job 就相当于来执行一个批处理任务,执行完就结束了,如果 Always 的话就陷入了死循环了。
backoffLimit说明
.spec.backoffLimit用于设置Job的容错次数,默认值为6。当Job运行的Pod失败次数到达.spec.backoffLimit次时,Job Controller不再新建Pod,直接停止运行这个Job,将其运行结果标记为Failure。另外,Pod运行失败后再次运行的时间间隔呈递增状态,例如10s,20s,40s。。。
CronJob
资源文件中Kind 变成了CronJob 了,要注意的是.spec.schedule字段是必须填写的,用来指定任务运行的周期,格式就和 crontab 一样,另外一个字段是.spec.jobTemplate, 用来指定需要运行的任务,格式当然和 Job 是一致的。
.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit,表示历史限制,是可选的字段,指定可以保留多少完成和失败的 Job,默认没有限制,所有成功和失败的 Job 都会被保留。
StatefullSet
在kubernetes系统中,Pod的管理对象RC,Deployment,DaemonSet和Job都面向无状态的服务,但现实中有很多服务时有状态的,比如一些集群服务,例如mysql集群,集群一般都会有这四个特点:
- 每个节点都是有固定的身份ID,集群中的成员可以相互发现并通信
- 集群的规模是比较固定的,集群规模不能随意变动
- 集群中的每个节点都是有状态的,通常会持久化数据到永久存储中
- 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损
如果通过RC或Deployment控制Pod副本数量来实现上述有状态的集群,就会发现第一点是无法满足的,因为Pod名称和ip是随机产生的,并且各Pod中的共享存储中的数据不能都动,因此StatefulSet在这种情况下就派上用场了,那么StatefulSet具有以下特性:
- StatefulSet里的每个Pod都有稳定,唯一的网络标识,可以用来发现集群内的其它成员,假设, StatefulSet的名称为lagou,那么第1个Pod叫lagou-0,第2个叫lagou-1,以此类推
- StatefulSet控制的Pod副本的启停顺序是受控的,操作第N个Pod时,前N-1个Pod已经是运行且准备状态
- StatefulSet里的Pod采用稳定的持久化存储卷,通过PV或PVC来实现,删除Pod时默认不会删除与 StatefulSet相关的存储卷(为了保证数据的安全)
StatefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与Headless,Service配合使用,每个StatefulSet定义中都要生命它属于哪个Handless Service,Handless Service与普通Service的关键区别在于,它没有Cluster IP
 wechat
wechat

