
k8s中pod生命周期详解
Pod阶段
使用kubectl get pods命令获取到的结果中,STATUS被称之为phase(个人理解为阶段,不过网上很多翻译为相位,相位的解释跟波有关,可自行百度)。
当然也可以通过kubectl explain pod.status命令来查看Pod状态的枚举值,Pod的状态定义在 PodStatus 对象中,其中有一个phase字段。
无论是手动创建还是通过控制器创建Pod,Pod对象总是应该处于其生命进程中以下几个阶段phase之一:
- 挂起(Pending):
apiserver创建了pod资源对象并存入etcd中,但是还没有被调度器调度到合适的节点或者镜像正在下载中; - 运行中(Running):Pod已经被调度至某节点,并且所有容器都已经被
kubelet创建完成。至少有一个容器正在运行,或者正处于启动或重启状态; - 成功(Succeeded):Pod中的所有容器都被成功终止,并且不会再重启;
- 失败(Failed):Pod中的所有容器都已终止了,但至少有一个容器是因为终止失败,容器以非0状态退出或者被系统终止;
- 未知(Unknown):因为某些原因
apiserver无法正常获取到Pod对象的状态信息,通常是因为与Pod所在节点通信失败导致的;
Pod在生命周期中状态的变化如下图: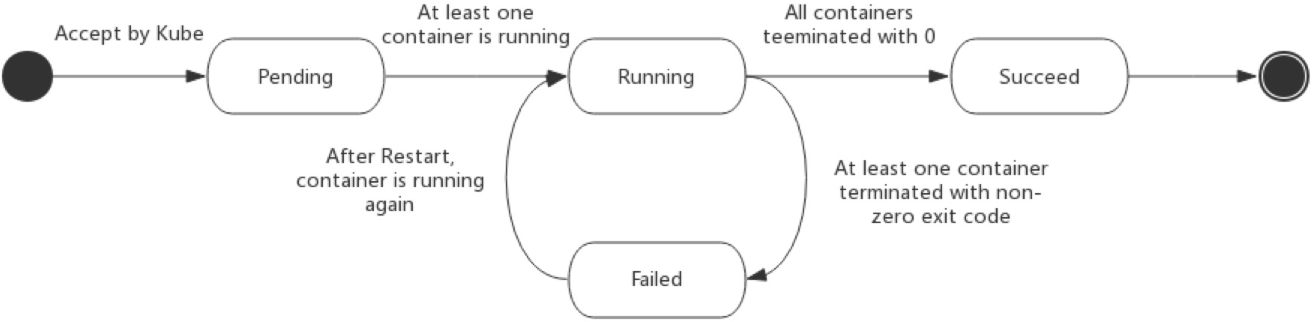
生命周期
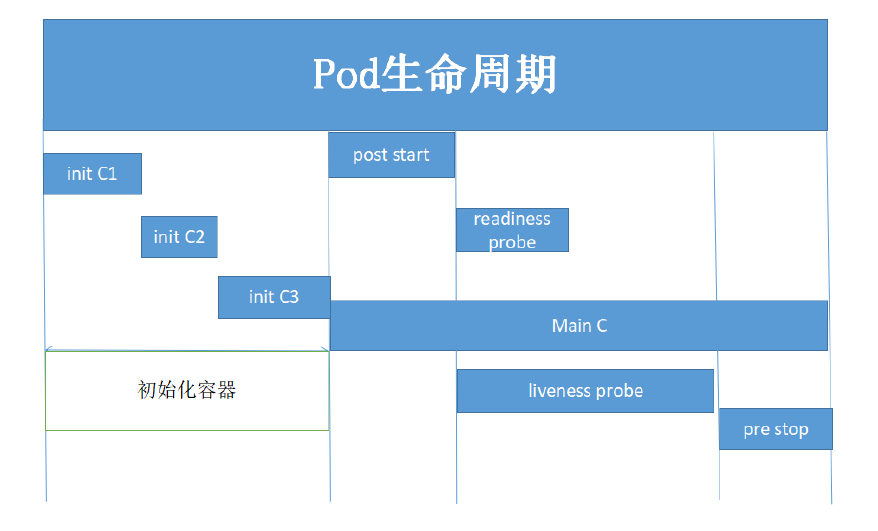
Pod的生命周期如图所示,具体解释如下:
initContainer
Init Container就是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行,只有所有的`初始化容器执行完之后,主容器才会被启动。
特点如下:
- initC总是运行到成功完成为止。
- 每个initC容器都必须在下一个initC启动之前成功完成。
- 如果initC容器运行失败,K8S集群会不断的重启该pod,直到initC容器成功为止。
- 如果pod对应的restartPolicy为never,它就不会重新启动。
其对应在资源清单yaml文件中,就是spec中initContainers配置。
初始化容器的应用场景:
- 等待其他模块 Ready:解决服务之间的依赖问题,比如Web 服务依赖于数据库服务,但是在启动这个 Web 服务的时候并不能保证数据库服务已经就绪,就可能会出现一段时间内 Web 服务连接数据库异常。要解决这个问题的话,就可以在 Web 服务的 Pod 中使用一个 InitContainer,去检查数据库是否已经准备好了,检查成功后Web 服务才被启动起来,这个时候去连接数据库就不会有问题了。
- 做初始化配置:比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。
- 其它场景:如将 Pod 注册到一个中央数据库、配置中心等。
mainContainer
当initC都成功完成之后,就会进行主容器的创建,例如上面的例子,web服务就是主容器。
健康检查
监控检查分为两类:
- readinessProbe(就绪检测):检测容器是否准备好服务请求,只有当Pod中的容器都处于就绪状态的时候,kubelet才会认定该Pod处于就绪状态。如果就绪探测失败,端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
- livenessProbe(存活检测):检测容器是否正在运行。如果存活探测失败,则kubelet会杀死容器,并且容器将受到其
重启策略的影响。如果容器不提供存活探针,则默认状态为Success。
其探测的方法有以下三种:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
任何一种探测方式都可能存在三种结果:
- success(成功):容器通过了诊断;
- failure(失败):容器未通过了诊断;
- unknown(未知):诊断失败,因此不会采取任何行动;
具体配置如下:
1 | # exec方式 |
一般就绪探针会在启动Pod一段时间后才开始第一次的就绪探测,之后做周期性探测。参数如下:
- initialDelaySeconds:在初始化容器多少秒后开始第一次就绪探测;
- timeoutSeconds:如果该次就绪探测超过多少秒后还未成功,判定为超时,该次探测失败,Pod不就绪。默认值1,最小值1;
- periodSeconds:如果Pod未就绪,则每隔多少秒周期性的做就绪探测。默认值10,最小值1;
- failureThreshold:如果容器之前探测成功,后续连续几次探测失败,则确定容器未就绪。默认值3,最小值1;
- successThreshold:如果容器之前探测失败,后续连续几次探测成功,则确定容器就绪。默认值1,最小值1。
Pod Hook
K8s提供了生命周期的钩子Pod Hook,Pod Hook 是由 kubelet 发起的,当容器中的进程启动前或者终止之前运行。
- PostStart: 于容器创建完成之后立即运行的钩子处理器(handler),不过k8s无法确保它一定会于容器中的entrypoint之前运行;
- PreStop:于容器终止操作之前立即运行的钩子处理器,它以同步的方式调用,因此在其完成之前会阻塞删除容器的操作调用;
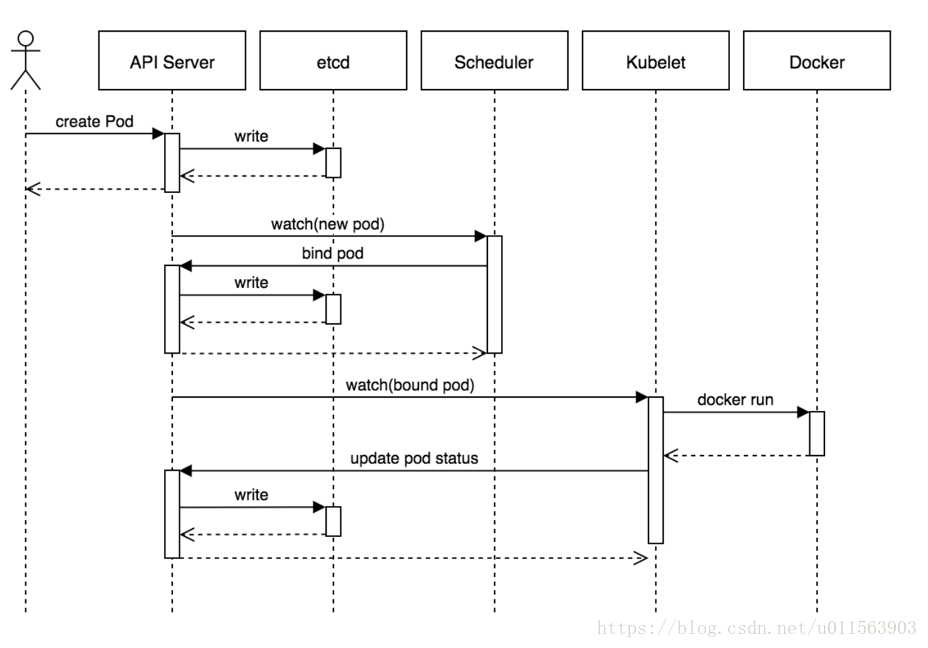
创建过程
以下为一个pod资源对象的典型创建过程:
- 用户通过kubectl或其他api客户端提交pod spec给api server;
- api server尝试着将pod对象的相关信息存入etcd中,待写入操作执行完成,api server即会返回确认信息至客户端;
- api server开始反映etcd中的状态变化;
- 所有的k8s组件均使用watch机制来跟踪检查api server上的相关变动;
- kube-scheduler通过其watch觉察到api server创建了新的pod对象但尚未绑定至任何工作节点;
- kube-scheduler为pod对象挑选一个工作节点并将结果信息更新至api server;
- 调度结果信息由api server更新至etcd,而且api server也开始反映此pod对象的调度结果;
- pod被调度到目标工作节点上的kubelet尝试在当前节点上调用docker启动容器,并将容器的结果状态回送至api server;
- 创建Infra 容器;
- 执行InitC;
- 初始化容器;
- 就绪检测;
- 存活检测;
- PostStart;
- 结束前的PreStop;
- api server将pod状态信息存入etcd中;
- 在etcd确认写入操作成功完成后,api server将确认信息发送至相关的kubelet;
重启策略
容器程序发生奔溃或容器申请超出限制的资源等原因都可能会导致pod对象的终止,此时是否应该重建该pod对象则取决于其重启策略(restartPolicy)属性的定义:
- Always:但凡pod对象终止就将其重启,此为默认设定
- OnFailure:尽在pod对象出现错误时方才将其重启
- Never:从不重启。
restartPolicy适用于pod对象中的所有容器,而且它仅用于控制在同一节点上重新启动pod对象的相关容器。首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长以此为10s、20s、40s、80s、160s和300s,300s是最大延迟时长,上限为 5 分钟,并在成功执行 10 分钟后重置。
事实上,一旦绑定到一个节点,pod对象将永远不会重新绑定到另一个节点,它要么被重启,要么终止,直到节点发生故障或被删除。
不同类型的的控制器可以控制 Pod 的重启策略:
- Job:适用于一次性任务如批量计算,任务结束后 Pod 会被此类控制器清除。Job 的重启策略只能是”OnFailure”或者”Never”。
- Replication Controller, ReplicaSet, or Deployment,此类控制器希望 Pod 一直运行下去,它们的重启策略只能是”Always”。
- DaemonSet:每个节点上启动一个 Pod,很明显此类控制器的重启策略也应该是”Always”。
终止过程
当用户提交删除请求之后,系统就会进行强制删除操作的宽限期倒计时,并将TERM信息发送给pod对象的每个容器中的主进程。宽限期倒计时结束后,这些进程将收到强制终止的KILL信号,pod对象随即也将由api server删除,如果在等待进程终止的过程中,kubelet或容器管理器发生了重启,那么终止操作会重新获得一个满额的删除宽限期并重新执行删除操作。
一个典型的pod对象终止流程具体如下:
- 用户发送删除pod对象的命令;
- api服务器中的pod对象会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead;
- 将pod标记为terminating状态;
- 与第三步同时运行,kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程;
- 与第三步同时运行,端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除;
- 如果当前pod对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行;若宽限期结束后,preStop仍未执行结束,则第二步会被重新执行并额外获取一个时长为2s的小宽限期;
- pod对象中的容器进程收到TERM信号;
- 宽限期结束后,若存在任何一个仍在运行的进程,那么pod对象即会收到SIGKILL信号;
- kubelet请求api server将此pod资源的宽限期设置为0从而完成删除操作,它变得对用户不再可见;
默认情况下,所有删除操作的宽限期都是30s,不过,kubectl delete命令可以使用“–grace-period=”选项自定义其时长,若使用0值则表示直接强制删除指定的资源,不过此时需要同时使用命令“–forece”选项。
 wechat
wechat

