
k8s service 笔记
Service 简介
通过Deployment来创建一组Pod来提供具有高可用性的服务。虽然每个Pod都会分配一个单独的Pod IP,然而却存在如下两问题:
- Pod IP仅仅是集群内可见的虚拟IP,外部无法访问。
- Pod IP会随着Pod的销毁而消失,当Deployment对Pod进行动态伸缩时,Pod IP可能随时随地都会变化。
在实际应用中,如果通过Nginx配置后端服务地址的话,由于 Pod ip 会出现变动,每次都需要手动修改配置文件,不方便。
当然也可以使用ZooKeeper或者ETCD等注册中心工具,实现服务的自动注册与发现,动态更新配置即可。
因此,Kubernetes中的Service对象就是解决以上问题的实现服务发现核心关键。
- Service能够提供负载均衡的能力,但是在使用上有以下限制。只提供
4 层负载均衡能力,而没有 7 层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的
代理 kube-proxy
一个Kubernetes的Service是一种抽象,它定义了一组Pods的逻辑集合和一个用于访问它们的策略(有的时候被称之为微服务)。一个Service的目标Pod集合通常是由Label Selector 来决定的。
Pod的IP实际路由到一个固定的目的地,而Service 的 IP 实际上不能通过单个主机来进行应答。相反,我们使用 iptables(Linux 中的数据包处理逻辑)来定义一个虚拟IP地址(VIP),它可以根据需要透明地进行重定向。当客户端连接到 VIP 时,它们的流量会自动地传输到一个合适的Endpoint。环境变量和 DNS,实际上会根据 Service 的 VIP 和端口来进行填充。
kube-proxy支持三种代理模式: 用户空间,iptables和IPVS;它们各自的操作略有不同。
Userspace代理模式
Client Pod要访问Server Pod时,它先将请求发给本机内核空间中的service规则(iptables),由它再将请求,转给监听在指定套接字上的kube-proxy,kube-proxy处理完请求,并分发请求到指定Server Pod后,再将请求递交给内核空间中的service,由service将请求转给指定的Server Pod。默认情况下对后端pod的选择是轮询。
由于其需要来回在用户空间和内核空间交互通信,因此效率很差 。
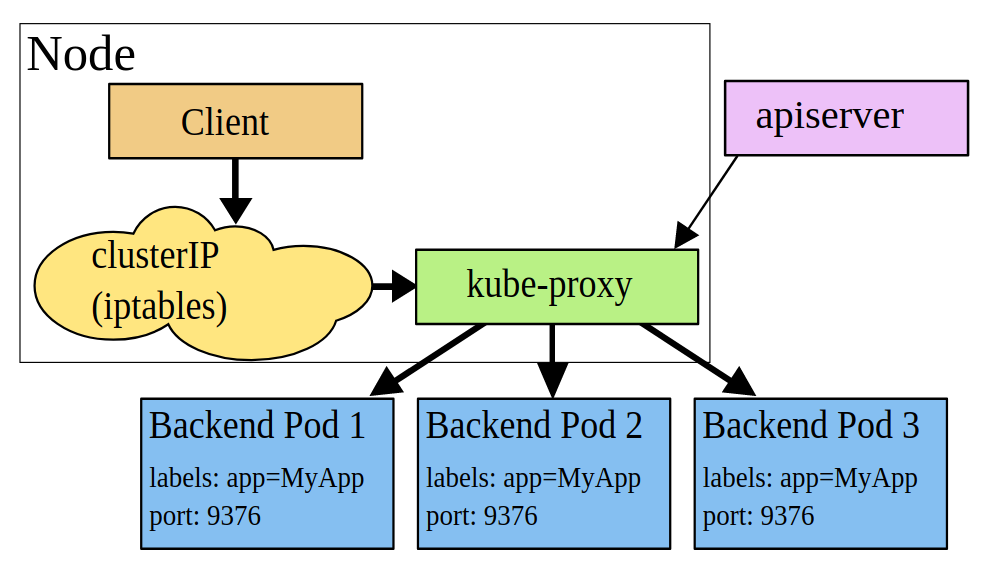
当一个客户端连接到一个 VIP,iptables 规则开始起作用,它会重定向该数据包到 Service代理的端口。Service代理选择一个backend,并将客户端的流量代理到backend 上。
这意味着 Service 的所有者能够选择任何他们想使用的端口,而不存在冲突的风险。客户端可以简单地连接到一个 IP 和端口,而不需要知道实际访问了哪些 Pod。
kube-proxy如果检测到与第一个Pod的连接失败,那么它会自动使用其他后端Pod进行重试。
iptables代理模式
当一个客户端连接到一个 VIP,iptables 规则开始起作用。一个 backend 会被选择(或者根据会话亲和性,或者随机),数据包被重定向到这个 backend。
kube-proxy 会监视 apiserver 对 Service 对象和 Endpoints 对象的添加和移除。对每个 Service,它会添加上 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某一个 Pod 上面。
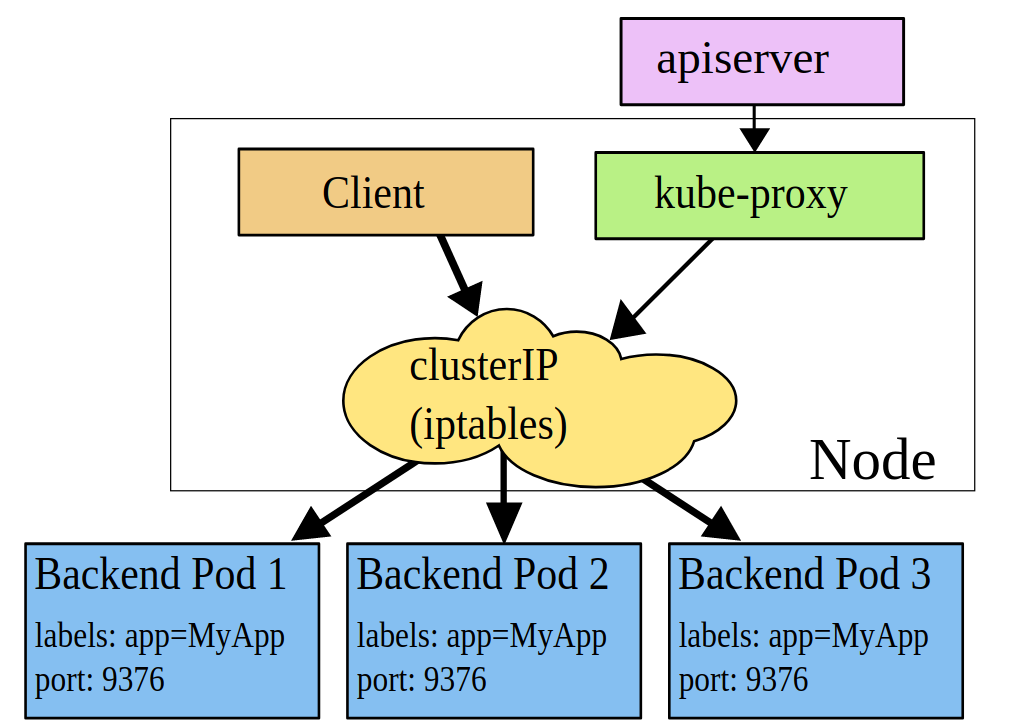
iptables 模式的 kube-proxy 默认的策略是,随机选择一个后端 Pod。
如果kube-proxy随机选择的Pod没有响应,那么此次连接失败。所以必须有就绪检测,防止异常。
iptables与用户空间区别
- 用户空间是kube-proxy对每个Service,它会在本地 Node 上打开一个端口(随机选择);
iptables是kube-proxy对每个 Service,它会添加上 iptables 规则; - 用户空间是捕获任何连接到“代理端口”的请求;
iptables是捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求;
IPVS代理模式
在 ipvs 模式下,kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。
此外,ipvs为负载均衡算法提供了更多选项,例如:
- rr:轮询调度(Round-Robin)
- lc:最小连接数(Least Connection),即打开链接数量最少者优先
- dh:目标哈希(Destination Hashing)
- sh:源哈希(Source Hashing)
- sed:最短期望延迟(Shortest Expected Delay)
- nq: 不排队调度(Never Queue)
ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
Service 类型
- ClusterIp:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP;
- NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 :NodePort 来访问该服务;
- LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部负载均衡器,并将请求转发到NodePort。是付费服务,而且价格不菲;
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持;
ClusterIP
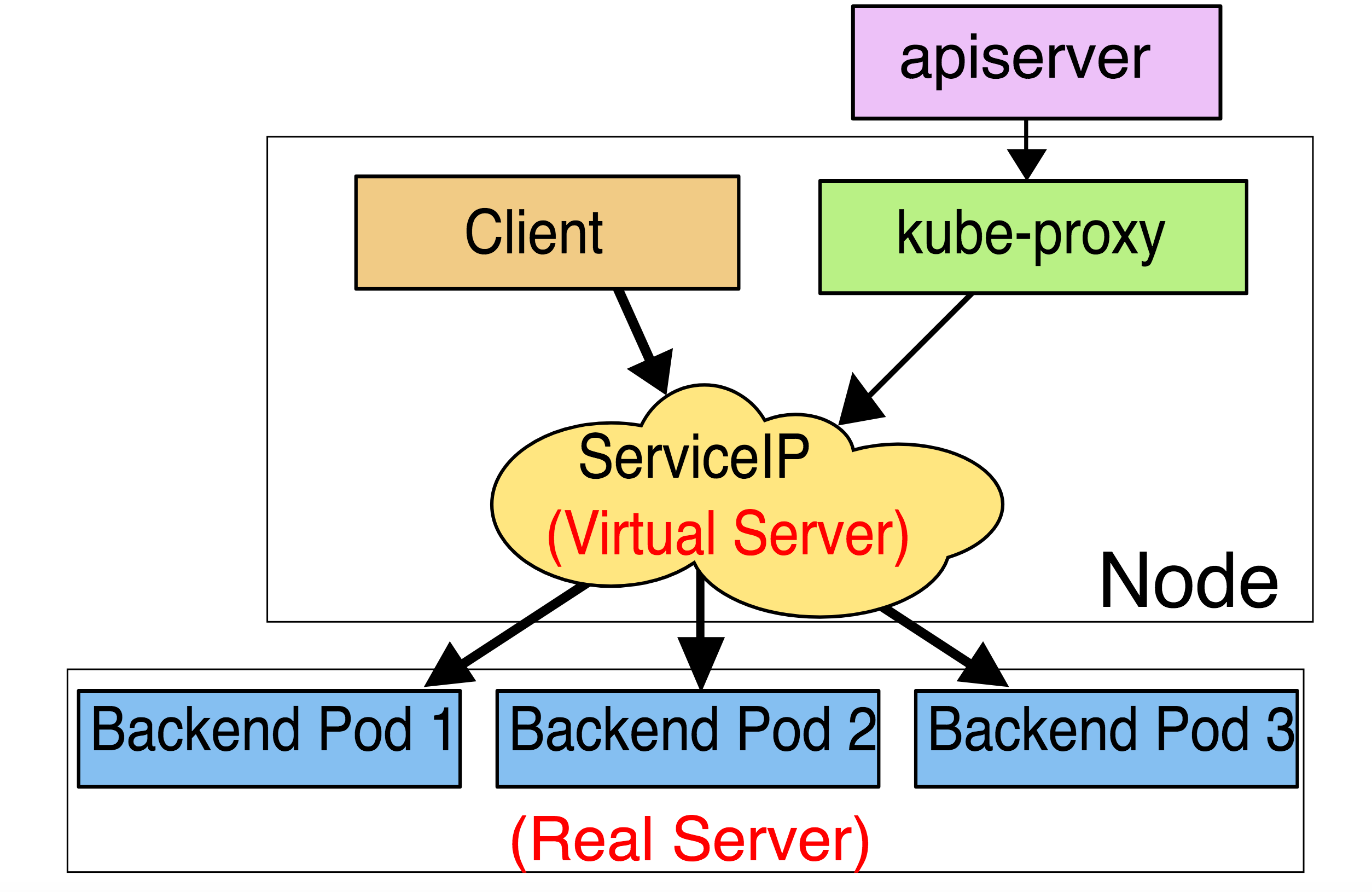
类型为ClusterIP的service,这个service有一个Cluster-IP,其实就一个VIP。具体实现原理依靠kubeproxy组件,通过iptables或是ipvs实现。
clusterIP 主要在每个 node 节点使用 iptables,将发向 clusterIP 对应端口的数据,转发到 kube-proxy中。然后 kube-proxy 自己内部实现有负载均衡的方法,并可以查询到这个 service 下对应 pod 的地址和端口,进而把数据转发给对应的 pod 的地址和端口。
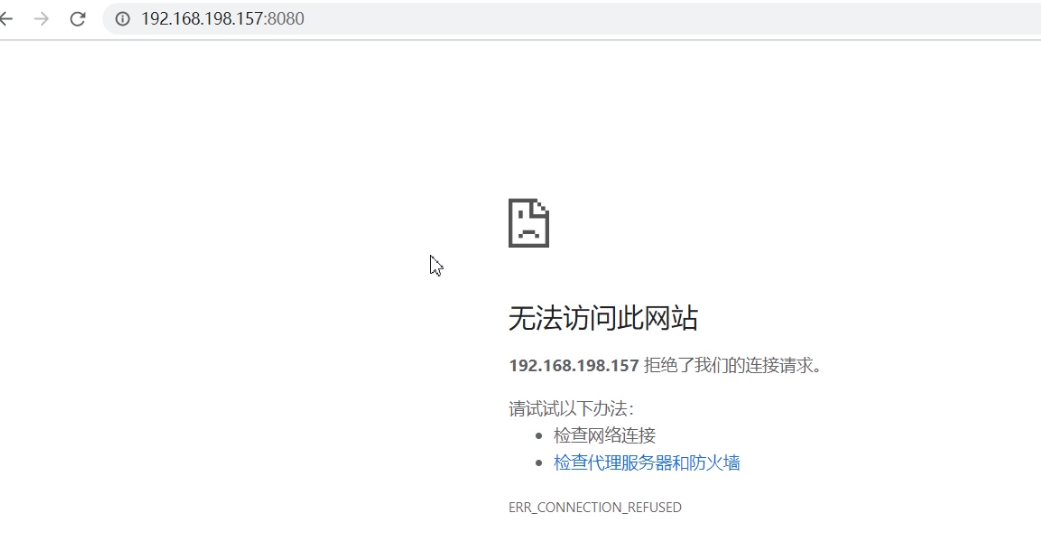
ClusterIP类型的service 只能在集群内访问,外部是无法访问的。
资源清单yaml示例:
1 | apiVersion: apps/v1 |
从外部进行访问时,会发现无法访问:
NodePort
当集群外的业务发起访问时,ClusterIP就无法满足不了。NodePort当然是其中的一种实现方案。nodePort 的原理在于在 node 上开了一个端口,将向该端口的流量导入到kube-proxy,然后由 kube-proxy 进一步到给对应的 pod 。
对于NodePort,Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定。
资源清单yaml示例:
1 | # ... deployment和clusterIp一样 |
然后从外部访问,如图所示:
LoadBalance
LoadBalancer类型的service 是可以实现集群外部访问服务的另外一种解决方案。不过并不是所有的k8s集群都会支持,大多是在公有云托管集群中会支持该类型。负载均衡器是异步创建的,关于被提供的负载均衡器的信息将会通过Service的status.loadBalancer字段被发布出去。
资源清单yaml示例:
1 | apiVersion: v1 |
来自外部负载均衡器的流量将直接打到 backend Pod 上,不过实际它们是如何工作的,这要依赖于云提供商。 在这些情况下,将根据用户设置的 loadBalancerIP 来创建负载均衡器。
ExternalName
ExternalName 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
1 | kind: Service |
当访问service-test时,集群的 DNS 服务将返回一个值为 my.redis.example.com 的 CNAME 记录。访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
服务发现
上面学习了 Service 的用法,我们可以通过 Service 生成的 ClusterIP(VIP) 来访问 Pod 提供的服务,但是在使用的时候还有一个问题:我们怎么知道某个应用的 VIP 是多少呢?
比如有两个应用,一个是 api 应用,一个是 db 应用,两个应用都是通过 Deployment 进行管理的,并且都通过 Service 暴露出了端口提供服务。api 需要连接到 db 这个应用,但是我们只知道 db 应用的名称和 db 对应的 Service 的名称,但是并不知道它的 VIP 地址,怎么解决呢?
对于这个问题存在两种方案:
- 环境变量
- DNS
环境变量
每个 Pod 启动的时候,会通过环境变量设置所有服务的 IP 和 port 信息,这样 Pod 中的应用可以通过读取环境变量来获取依赖服务的地址信息,这种方法使用起来相对简单,但是有一个很大的问题就是依赖的服务必须在 Pod 启动之前就存在,不然是不会被注入到环境变量中的。
当然我们可以通过initContainer之类的方法来确保依赖服务启动后再启动当前的Pod,但是这种方法毕竟增加了 Pod 启动的复杂性,所以这不是最优的方法,局限性太多了。
举个例子,一个名称为 “redis-master” 的 Service 暴露了 TCP 端口 6379,同时给它分配了 Cluster IP 地址 10.0.0.11,这个 Service 生成了如下环境变量:
1 | REDIS_MASTER_SERVICE_HOST=10.0.0.11 |
DNS
由于我们只知道service的名称,那是否可以直接使用 Service 的名称呢?因为 Service 的名称不会变化,我们不需要去关心分配的 ClusterIP 的地址,因为这个地址并不是固定不变的,所以如果我们直接使用 Service 的名字,然后对应的 ClusterIP 地址的转换能够自动完成就很好了。
而名称与IP的自动转换,就可以通过DNS来解决,同样的,Kubernetes 也提供了 DNS 的方案来解决上面的服务发现的问题。
DNS 服务不是一个独立的系统服务,而是作为一种 addon 插件而存在,现在比较推荐的两个插件:kube-dns 和 CoreDNS,实际上在比较新点的版本中已经默认是 CoreDNS 了。
因为 kube-dns 默认一个 Pod 中需要3个容器配合使用,CoreDNS 只需要一个容器即可。
CoreDNS 的 Service 地址一般情况下是固定的,类似于 kubernetes 这个 Service 地址一般就是第一个 IP 地址10.96.0.1,CoreDNS 的 Service 地址就是10.96.0.10,该 IP 被分配后,kubelet 会将使用--cluster-dns=<dns-service-ip> 参数配置的 DNS 传递给每个容器。DNS 名称也需要域名,本地域可以使用参数--cluster-domain = <default-local-domain> 在 kubelet 中配置。
如下所示:
1 | cat /var/lib/kubelet/config.yaml |
利用 kubedns 将 Service 生成 DNS 记录有两种情况:
- 普通的 Service:会生成
servicename.namespace.svc.cluster.local的域名,会解析到 Service 对应的 ClusterIP 上,在 Pod 之间的调用可以简写成servicename.namespace,如果处于同一个命名空间下面,甚至可以只写成servicename即可访问 - Headless Service:无头服务,就是把 clusterIP 设置为 None 的,会被解析为指定 Pod 的 IP 列表,同样还可以通过
podname.servicename.namespace.svc.cluster.local访问到具体的某一个 Pod。
ingress网络
简介
通过上面的学习可知,如果需要让集群外部访问内部的服务,目前已有两种方法:NodePort 和 LoadBlancer,除此之外还提供了ingress的方式,当NodePort配置过多的时候,管理起来也比较麻烦,使用ingress就方便了很多。
其实Ingress就是从 Kuberenets 集群外部访问集群的一个入口,将外部的请求转发到集群内不同的 Service 上,就相当于 nginx、haproxy 等负载均衡代理服务器。
组成部分
ingress由两部分组成:ingress controller和ingress服务。
- ingress对象: 指的是k8s中的一个api对象,一般用yaml配置。作用是定义请求如何转发到service的规则,可以理解为配置模板。
- ingress-controller: 具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发。
Ingress Controller 可以理解为一个监听器,通过不断地监听 kube-apiserver,实时的感知后端 Service、Pod 的变化,当得到这些信息变化后,Ingress Controller 再结合 Ingress 的配置,更新反向代理负载均衡器,达到服务发现的作用。
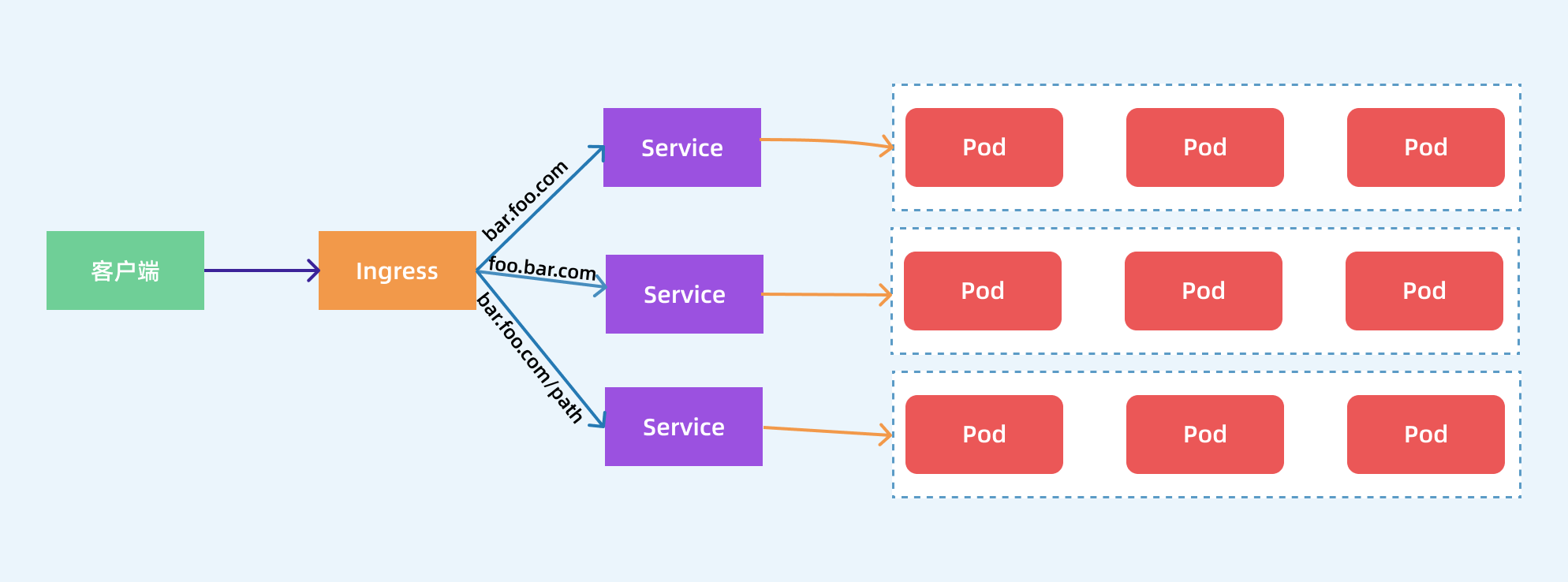
其中ingress controller目前主要有两种:基于nginx服务的ingress controller和基于traefik的ingress controller。
这里只记录了基于nginx服务的ingress controller,它的使用比较常见。
NGINX Ingress Controller
Ingress-nginx组成
- 反向代理负载均衡器:通常以service的port方式运行,接收并按照ingress定义的规则进行转发,常用的有nginx,Haproxy,Traefik等,本次实验中使用的就是nginx。
- Ingress Controller:监听APIServer,根据用户编写的ingress规则(编写ingress的yaml文件),动态地去更改nginx服务的配置文件,并且reload重载使其生效,此过程是自动化的(通过lua脚本来实现)。
- Ingress:将nginx的配置抽象成一个Ingress对象,当用户每添加一个新的服务,只需要编写一个新的ingress的yaml文件即可。
Ingress-nginx的工作原理
- ingress controller通过和kubernetes api交互,动态的去感知集群中ingress规则变化。然后读取它,按照自定义的规则(规则就是写明了那个域名对应哪个service),生成一段nginx配置。
- 再写到nginx-ingress-controller的pod里,这个Ingress controller的pod里运行着一个Nginx服务,控制器会把生成的nginx配置写入/etc/nginx.conf文件中。然后reload一下使配置生效,以此达到分配和动态更新问题。
流程解析
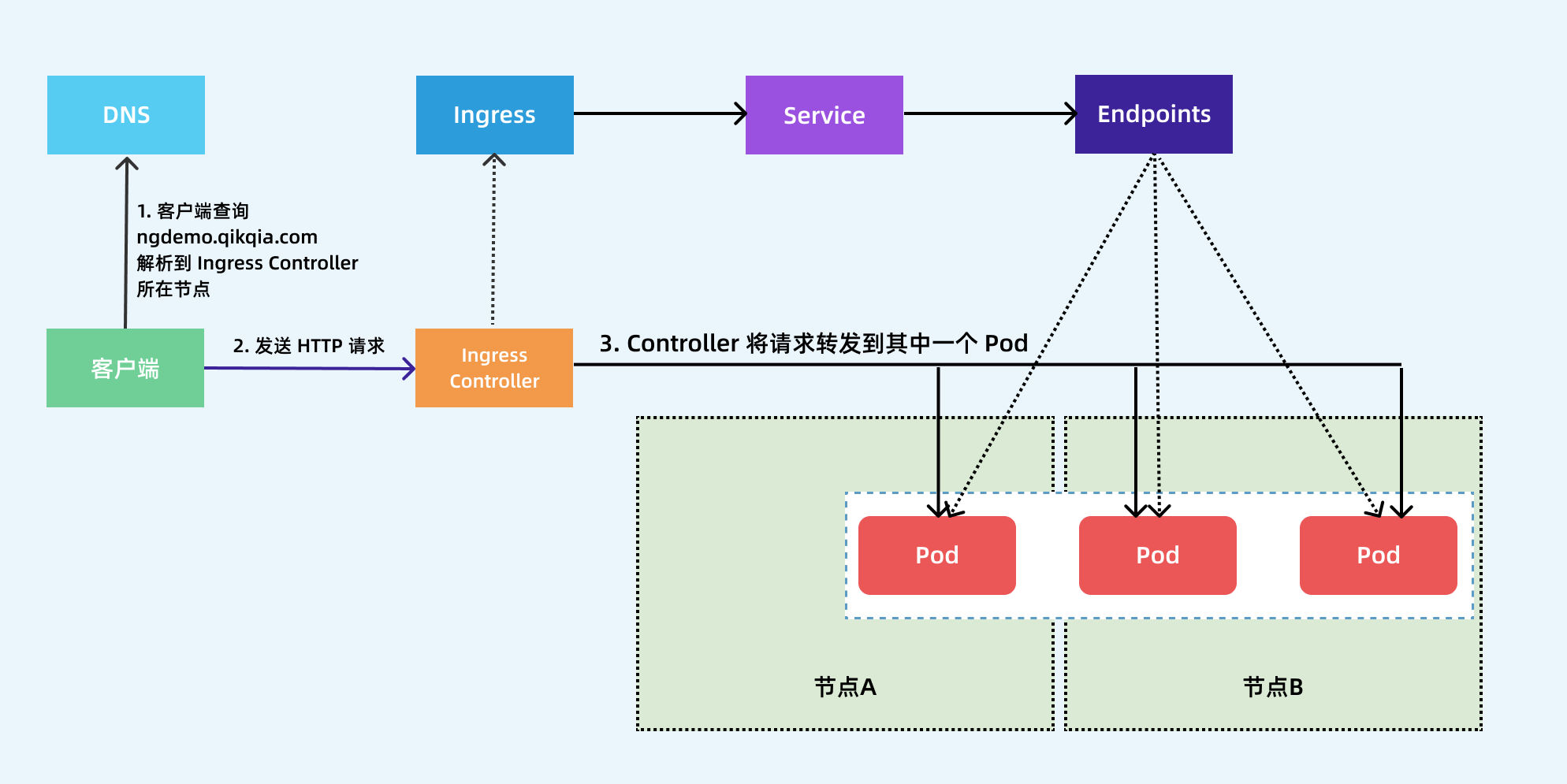
- 客户端首先对 ngdemo.qikqiak.com 执行 DNS 解析,得到 Ingress Controller 所在节点的 IP;
- 然后客户端向 Ingress Controller 发送 HTTP 请求,然后根据 Ingress 对象里面的描述匹配域名,找到对应的 Service 对象,并获取关联的 Endpoints 列表;
- 最终将客户端的请求转发给其中一个 Pod。
资源清单示例
简单规则如下:
1 | apiVersion: extensions/v1beta1 |
注意:这种方式只能通过ingress-controller部署的节点访问。集群内其他节点无法访问ingress规则。
域名访问ingress规则如下:
1 | apiVersion: extensions/v1beta1 |
 wechat
wechat

