mybatis架构简介
Mybatis的架构可以大致分为以下三层:
Mybatis作为一个ORM框架,实际上底层还是通过JDBC来操作数据库,完成增删改查的。
想要详细了解底层的原理,首先需要知道Mybatis的九大核心的概念:
组件
描述
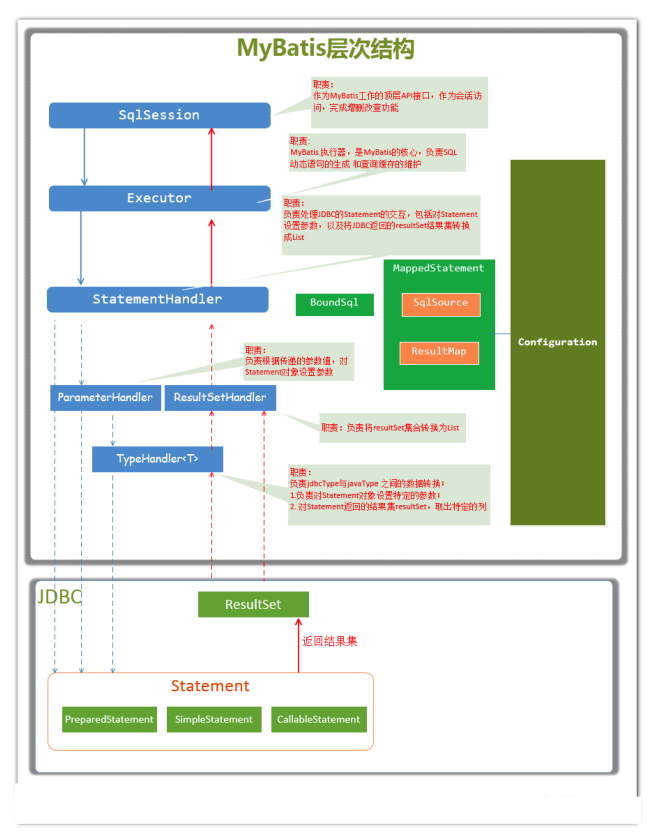
SqlSession
作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成数据库增删改查功能
Executor
MyBatis执行器,是MyBatis调度的核心,负责SQL语句的生成和查询缓存的维护
StatementHandler
封装了JDBC Statement操作,负责对JDBC statement的操作,如设置参数、将Statement结果集转换成List集合
ParameterHandler
负责对用户传递的参数转换成JDBC Statement所需要的参数
ResultSetHandler
负责将JDBC返回的ResultSet结果集对象转换成List类型的集合
TypeHandler
负责java数据类型和jdbc数据类型之间的映射和转换
MappedStatement
MappedStatement维护了一条<select | update | delete | insert>节点的封装
SqlSource
负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回
BoundSql
表示动态生成的SQL语句以及相应的参数信息
Mybatis完成一次查询或者其他操作的大致流程如下图所示:
层次结构图如下:
简单描述Mybatis执行过程如下:
加载核心配置文件,得到数据库连接信息,创建核心配置对象保存生成的连接池等信息;
加载映射配置文件,将namespace和SQL语句标签的id,组合作为id,最终封装成为一个MappedStatement对象,存放到内存中;
调用OpenSession方法获得会话,然后调用相应的增删改查方法,方法参数为namespace+id;
接收到处理请求,由Executor的默认实现类BaseExecutor来处理,首先封装BoundSql对象,并根据分页等信息生成缓存的Key;
判断缓存中是否有,如果有则返回,如果没有进行数据库的查询;
进入SimpleExecutor中进行数据库的查询,调用StatementHandler来处理,而它先通过ParameterHandler进行参数设置,通过TypeHandler将java类型转换成为数据库类型;
最终调用JDBC的操作,完成查询,得到ResultSet;
然后通过ResultSetHandler处理器将结果进行处理,最终返回指定的结果类型;
mybatis源码分析 首先,通过传统模式调用mybatis的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test public void test () throws IOException InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml" ); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession sqlSession = sqlSessionFactory.openSession(); List<User> users = sqlSession.selectList("user.findAll" ); for (User user : users) { System.out.println(user); } sqlSession.close(); }
这种传统方式的缺点也很明显,namespace+id是硬编码,如果很多地方使用时,发生变化,则需要修改所有的地方。getMapper的方式,无需指定:
1 2 3 4 5 6 7 8 9 10 11 @Test public void test () throws IOException InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml" ); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); SqlSession sqlSession = sqlSessionFactory.openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> userList= mapper.findAllUser(); for (User user : userList) { System.out.println(user); } }
这种代理方式是如何实现的呢?SqlSession的实现类DefaultSqlSession一直到MapperProxyFactory最终找到具体的实现方式:
1 2 3 4 5 6 7 8 9 10 11 protected T newInstance (MapperProxy<T> mapperProxy) return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[]{mapperInterface}, mapperProxy); } public T newInstance (SqlSession sqlSession) final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache); return newInstance(mapperProxy); }
到此处我们可以确定Mybatis是通过JDK动态代理的方式进行代理对象的产生。
同时,这里也可以解释为什么Mybatis规定Mapper的namespace要和mapper的全限定名一致,为什么SQL语句的id要与方法名一致。
通过JDK动态代理的参数可知,最终是由MapperProxy来进行的代理增强,进入其中查看invoke发现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public Object invoke (Object proxy, Method method, Object[] args) throws Throwable try { if (Object.class.equals(method.getDeclaringClass())) { return method.invoke(this , args); } else if (isDefaultMethod(method)) { return invokeDefaultMethod(proxy, method, args); } } catch (Throwable t) { throw ExceptionUtil.unwrapThrowable(t); } final MapperMethod mapperMethod = cachedMapperMethod(method); return mapperMethod.execute(sqlSession, args); }
所以最终通过method参数获取到要执行的是哪个SQL,最终交给mapperMethod完成执行,进行上面讲的步骤,最终得到结果。
插件原理与自定义 插件对mybatis来说就是拦截器,用来增强核心对象的功能,增强功能本质上是借助于底层的动态代理实现的。
Mybatis对持久层的操作就是借助于四大核心对象,Executor、StatementHandler、ParameterHandler、ResultSetHandler,在上面分析源码时,会发现这四大核心对象都有拦截判断,我们就是通过拦截这四大对象来进行插件的开发。
进入org.apache.ibatis.session.Configuration核心配置类中,可以看到针对Executor的拦截器判断:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public Executor newExecutor (Transaction transaction, ExecutorType executorType) executorType = executorType == null ? defaultExecutorType : executorType; executorType = executorType == null ? ExecutorType.SIMPLE : executorType; Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this , transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this , transaction); } else { executor = new SimpleExecutor(this , transaction); } if (cacheEnabled) { executor = new CachingExecutor(executor); } executor = (Executor) interceptorChain.pluginAll(executor); return executor; }
针对ParameterHandler的插件加载:
1 2 3 4 5 6 7 public ParameterHandler newParameterHandler (MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql); parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler); return parameterHandler; }
针对StatementHandler 插件加载:
1 2 3 4 5 6 7 public StatementHandler newStatementHandler (Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler); return statementHandler; }
针对ResultSetHandler插件加载:
1 2 3 4 5 6 7 8 public ResultSetHandler newResultSetHandler (Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler, ResultHandler resultHandler, BoundSql boundSql) ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds); resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler); return resultSetHandler; }
通过上面的源码我们会发现,在这四大对象创建的时候会进行插件的加载,而且加载的方法是相同的,都是interceptorChain.pluginAll(),所以我们进入该方法,查看具体的加载逻辑:
1 2 3 4 5 6 public Object pluginAll (Object target) for (Interceptor interceptor : interceptors) { target = interceptor.plugin(target); } return target; }
在深入进入会发现如下逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static Object wrap (Object target, Interceptor interceptor) Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor); Class<?> type = target.getClass(); Class<?>[] interfaces = getAllInterfaces(type, signatureMap); if (interfaces.length > 0 ) { return Proxy.newProxyInstance( type.getClassLoader(), interfaces, new Plugin(target, interceptor, signatureMap)); } return target; }
通过上面的源码,我们发现最终拦截器或者插件的实现原理就是通过JDK动态代理来实现的。
interceptorChain保存了所有的拦截器(interceptors),在Mybatis初始化的时候创建。interceptor.plugin(target)中的target就可以理解为要被拦截的四大对象。返回的target就是被重重代理后的对象。
这时候如果我们想要自定义一个插件,只需要实现Mybatis的Interceptor接口,重写其中的方法就行了,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Intercepts({ @Signature(type= StatementHandler.class, method = "prepare", args = {Connection.class,Integer.class}) }) public class MyPlugin implements Interceptor @Override public Object intercept (Invocation invocation) throws Throwable System.out.println("对方法进行了增强...." ); return invocation.proceed(); } @Override public Object plugin (Object target) Object wrap = Plugin.wrap(target, this ); return wrap; } @Override public void setProperties (Properties properties) System.out.println("获取到的配置文件的参数是:" +properties); } }
通过@Intercepts和@Signature注解,可以指定自定义的拦截器(插件)是在哪个类的哪个方法执行时进行拦截,可以定义多个@Signature,同时对多个方法进行拦截。
当然,插件开发完毕后,也不是直接就会生效,还需要将其配置到Mybatis的核心配置文件中:
1 2 3 <plugins > <plugin interceptor ="com.jfl.test.plugin.MyPlugin" > </plugin > </plugins >
配置之后,在Mybatis启动时就会将这个插件放入interceptorChain中,最终生成代理对象完成增强的方法的执行。



 wechat
wechat

